An accident and investigation of the server failure
In this post, I am going to share an accident I had recently with in-house production.
Let’s assume we have an SSH server. Clients who call commands through it. Quite simple, right?
Of course, we cannot have only one SSH server. Instead, we run several SSH servers and use HAProxy to load-balance traffic to them. It is way more safe to have several servers, instead of one. For example, it simplifies maintenance, allows to easily implement Rolling Updates or say A/B Testing. I wrote in a previous post more details on our HAProxy setup some time ago
The outage as seen by users
At some day, our users (as I can recreate from reports) started to see strange connection timeouts from SSH server calls. The call they did was to download several gigabytes of data.
From a user perspective, it’s totally OK to retry a command once it failed for the very first time. So they did it.
After several retries, they tend to give up. At that time our system was no longer capable of serving any SSH requests at all
The outage as seen from the server-side
We are running several SSH servers behind HAProxy. Servers were running in JVM. I use amazing Apache Mina SSHD to implement our SSH server.
Alerts appeared for our SSH servers. HAProxy started to drain traffic from dead SSH servers, based on health checks. It was good since other requests were still able to execute on still live servers.
There were only two servers in our setup. So the system was too fast to be killed.
All dead server had an out-of-memory (OOM) before death. Sadly, but it is hard to write an application that is can survive OOMs and continue to function. In our case, OOM tended to kill either SSH server socket processing for either SSH or HTTP.
The good side was that those SSH servers had not sensible state. Thus it was easy to restart them to be back in business. So we had the workaround
Java heap dump analysis
By that time I had several memory dumps (.hprof) files from failed servers. It was time to analyze what is there. All those failures were only because a send buffer was full of data, consuming the rest of heap memory. More detailed, I found a massive SSH session object.
With more analysis, I found the whole memory was consumed by the write queue.
A closer look in memory dumps and I was able to figure out the outage was caused by
a fresh Putty client on Windows, e.g.
SSH-2.0-PuTTY_Release_0.69. At the time of the accident, it was the most recent version.
The state was that I had an OOM issue downloading several gigabytes of data over the
SSH with Putty client. It was time to write integration tests to reproduce the problem.
I did it. I was able to test every putty client version. I tried 0.67, 0.68 and 0.69.
The OOM problem was likely to be introduced in 0.68.
Client problem and users
Memory snapshot analysis was helpful to realize the problem was with a specific version of an SSH client. I also knew, only users with fresh computers we reporting the issue too.
It was evident I cannot do anything with the client. Users decided to use it for their reasons. Also, my SSH server implementation did not support the client filtering. Anyway, I’d be too hard to explain everyone the problem is probably with recent update of their software.
Debugging the problem
Thanks to integration tests I did, I was also able to debug the problem and realize the cause of the issue.
I found the method, which handles all writes on the server:
org.apache.sshd.common.session.AbstractSession#writePacket(org.apache.sshd.common.util.buffer.Buffer)
Apache Mina SSHD server is async. Instead of writing data directly to the socket it enqueues the data and sends once the OS is ready for it.
Also, the implementation writes messages to a dedicated queue while re-key process is running. This method is called for every SSH command channel writes too. SSH window size is checked before calling the method, so the command writer is blocked to wait while queued messages are sent.
In memory dumps of the session object, I saw the window was barely unlimited.
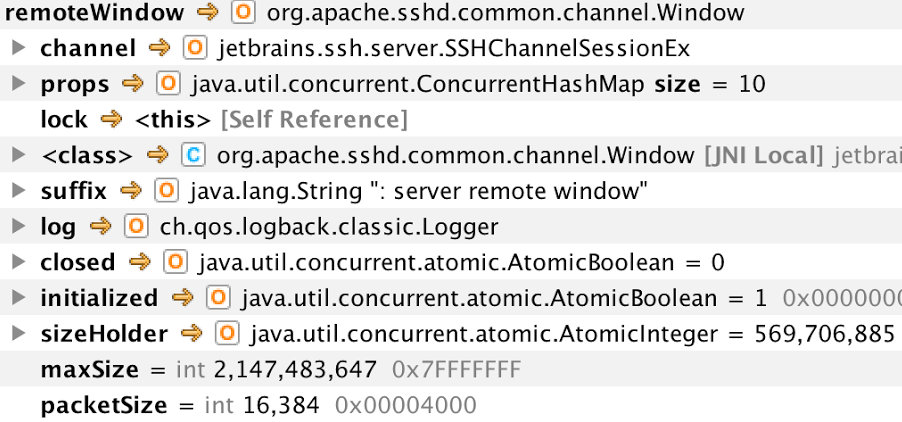
Having unlimited window and a slow network is enough for a server to consume all memory with messages queue. In my case SSH, command was streaming several gigabytes of data from memory.
There are two questions:
- Why is it happening only now?
- How can we avoid the problem?
SSH window abuse
As we know, SSH protocol uses windows to limit the number of data being queued. Why didn’t it work?
It was easy to debug. I found out Putty was sending 2GB (e.g., signed integer max value) as the size of the receive window. Well, I saw no reason why. But having such a huge send window makes SSH server enqueue up to 2GB of data per session.
An optimistic approach, as we are a victim of it, is to trust SSH client and use the window as-is.
A defensive approach is to have an additional send window in SSH server to avoid blindly trusting a client.
SSHD patch
Now it was more or less clear. The problem was in unlimited write queue and infinite send window. I created an issue for the Apache Mina SSHD project to let anyone know there is such a problem.
https://issues.apache.org/jira/browse/SSHD-754
I did a trivial patch on for the server. I decided to limit write queue for channel messages to block the sender even in the case send window is unlimited. I simply use a semaphore for it:
private val CHANNEL_STDOUT_LOCK = PressureLock()
private val CHANNEL_STDERR_LOCK = PressureLock()
override fun writePacket(buffer: Buffer): IoWriteFuture {
// The workaround for
// https://issues.apache.org/jira/browse/SSHD-754
// the trick is to block writer thread once there are more
// than 100 messages in either rekey wait queue or nio write queue
val lock = when (buffer.array()[buffer.rpos()]) {
SshConstants.SSH_MSG_CHANNEL_DATA -> CHANNEL_STDOUT_LOCK
SshConstants.SSH_MSG_CHANNEL_EXTENDED_DATA -> CHANNEL_STDERR_LOCK
else -> null
}?.acquire()
val future = super.writePacket(buffer)
if (lock != null) {
future.addListener(lock)
}
return future
}
}The code above is included in my inheritor of the org.apache.sshd.common.session.AbstractSession.
I like Apache Mina SSHD library is designed in an extensible way making such workaround possible.
And the PressureLock was implemented this way:
class PressureLock {
private val semaphore = Semaphore(100)
private val listener = object : SshFutureListener<IoWriteFuture?> {
override fun operationComplete(future: IoWriteFuture?) {
semaphore.release()
}
}
fun acquire() : SshFutureListener<IoWriteFuture?> {
semaphore.acquire()
return listener
}
}I checked the fix with my tests. The problem was solved.
Putty changes
With integration tests, I was able to detect that it started to fail only with Putty 0.68. Putty 0.67 was working great. Also, all our problems were only from putty SSH clients on Windows.
I decided to dig dipper and see, that change was it. Sadly, there were so many changes between 0.67 and 0.68. Also, it took several years for them too.
I knew I was looking the change to windows size. I confirmed in debugger, Putty 0.67 was using 16K for it.
And I found the change b22c0b6f3e6f5254270a89f86df3edfc4da829d2 and the winplink.c file
--- a/windows/winplink.c
+++ b/windows/winplink.c
@@ -618,6 +618,17 @@ int main(int argc, char **argv)
return 1;
}
+ /*
+ * Plink doesn't provide any way to add forwardings after the
+ * connection is set up, so if there are none now, we can safely set
+ * the "simple" flag.
+ */
+ if (conf_get_int(conf, CONF_protocol) == PROT_SSH &&
+ !conf_get_int(conf, CONF_x11_forward) &&
+ !conf_get_int(conf, CONF_agentfwd) &&
+ !conf_get_str_nthstrkey(conf, CONF_portfwd, 0))
+ conf_set_int(conf, CONF_ssh_simple, TRUE);
+The change was to flip CONF_ssh_simple mode on Windows. The change
did enable 2GB receive window, as you may see from the usages.
In ssh.c in Putty 0.70 we have defines:
#define OUR_V2_BIGWIN 0x7fffffff
#define OUR_V2_WINSIZE 16384And the code-block:
static int ssh_is_simple(Ssh ssh)
{
/*
* We use the 'simple' variant of the SSH protocol if we're asked
* to, except not if we're also doing connection-sharing (either
* tunnelling our packets over an upstream or expecting to be
* tunnelled over ourselves), since then the assumption that we
* have only one channel to worry about is not true after all.
*/
return (conf_get_int(ssh->conf, CONF_ssh_simple) &&
!ssh->bare_connection && !ssh->connshare);
}
/*
* Set up most of a new ssh_channel.
*/
static void ssh_channel_init(struct ssh_channel *c)
{
Ssh ssh = c->ssh;
c->localid = alloc_channel_id(ssh);
c->closes = 0;
c->pending_eof = FALSE;
c->throttling_conn = FALSE;
if (ssh->version == 2) {
c->v.v2.locwindow = c->v.v2.locmaxwin = c->v.v2.remlocwin =
ssh_is_simple(ssh) ? OUR_V2_BIGWIN : OUR_V2_WINSIZE;
c->v.v2.chanreq_head = NULL;
c->v.v2.throttle_state = UNTHROTTLED;
bufchain_init(&c->v.v2.outbuffer);
}
add234(ssh->channels, c);
}The windows size is computed by the following expression:
c->v.v2.locwindow = c->v.v2.locmaxwin = c->v.v2.remlocwin =
ssh_is_simple(ssh) ? OUR_V2_BIGWIN : OUR_V2_WINSIZE;The windows sizes are exactly the same as I saw in debugger both for
0.67 and 0.69 versions.
That was it. And it was in April 2016. It took more than a year for the change to cause the issues I was debugging.
Thanks to the opensource, I was able to dig that deep to see the source of the problem. I liked it.
Conclusion
I was running these SSH servers for more than a year. I like people say, ‘Hey, I did no changes to anything, why is it failing now?’
It was indeed the change. And the system started to fail. It was the outer world that changed.
I found the source of the issue and did a patch to make the server work again with new SSH clients. That was fun!