Listing files, it’s an easy task, isn’t it? I remember myself doing that as part of my computer science classes many years ago. What if one has about a million of files to list? That could be way more interesting.
You may say, 1 million of files, is that possible at all? Yes, it actually
not hard to find under a checkout folder of a medium project. A compiler
output directory is likely to double the size of files you have (e.g. with .obj or .class files).
The experiments and measurements I do are executed on the Apple MacBook Pro (15-inch, 2019, 2,4 GHz 8-Core Intel Core i9, 32Gb, Apple SSD AP0512M, 512Gb) running macOS Catalina 10.15.6 (19G73). I use an encrypted case-insensitive APFS on the whole SSD.
The Find Utility
Let’s start with a baseline experiment, for that we just call the find command in the console:
bash-3.2$ find . | wc -l
942330
bash-3.2$ find . -type f | wc -l
800205
bash-3.2$ find . -type d | wc -l
141981
We use the wc command to count lines in
the output of the find command.
With the help of | we pipe the
output of the find command to the wc command.
There are 942330 items under the working directory, 800205 files, 141981 directories.
I have some symlinks from macOS Frameworks and node_modules.
bash-3.2$ time find . > /dev/null
real 0m30.977s
user 0m0.796s
sys 0m12.034s
I’ve made several runs, yielding the time around 31 seconds (30.977, 33.643, 31.497).
Git Status
My working directory is under Git version control. The .gitignore makes
Git to ignore the compiler output folders. The status command works a bit faster, but still time-taking:
bash-3.2$ time git status
It took 4.59 seconds to enumerate untracked files. 'status -uno'
may speed it up, but you have to be careful not to forget to add
new files yourself (see 'git help status').
nothing added to commit but untracked files present (use "git add" to track)
real 0m9.217s
user 0m1.427s
sys 0m58.756s
I’ve made several runs, it shows the time around 8.5 seconds
(9.046, 8.179, 9.217, 8.383, 8,461, 8.726).
Java
I decided to try Java implementation to see if it works faster.
For the experiment I use OpenJDK 14.0.1 on the same macOS.
We can collect all files in Java with the Files.walk API:
public static void main(String[] args) throws IOException {
for(int i = 0; i < 5; i++) {
Instant start = Instant.now();
long size = Files.walk(home).count();
Duration duration = Duration.between(start, Instant.now());
System.out.println("Total files: " + size + ", done in " + duration);
}
}
It prints:
Total files: 942330, done in PT45.623236S
Total files: 942330, done in PT49.75288S
Total files: 942330, done in PT49.52438S
Total files: 942330, done in PT48.5415S
Total files: 942330, done in PT49.18739S
On my machine the program managed to complete in approximately 49 seconds
(45.623236,49.75288, 49.52438, 48.5415,49.18739). I’ve added the loop
in the program with a hope to warmup
the JVM.
Parallel execution via Stream.parallel() did not help at all on my 8-core machine. Similarly,
the Files.walkFileTree API does not give any sensible performance win.
Quick CPU profile in IntelliJ IDEA
shown the most of the time it was spending calling the lstat POSIX function:
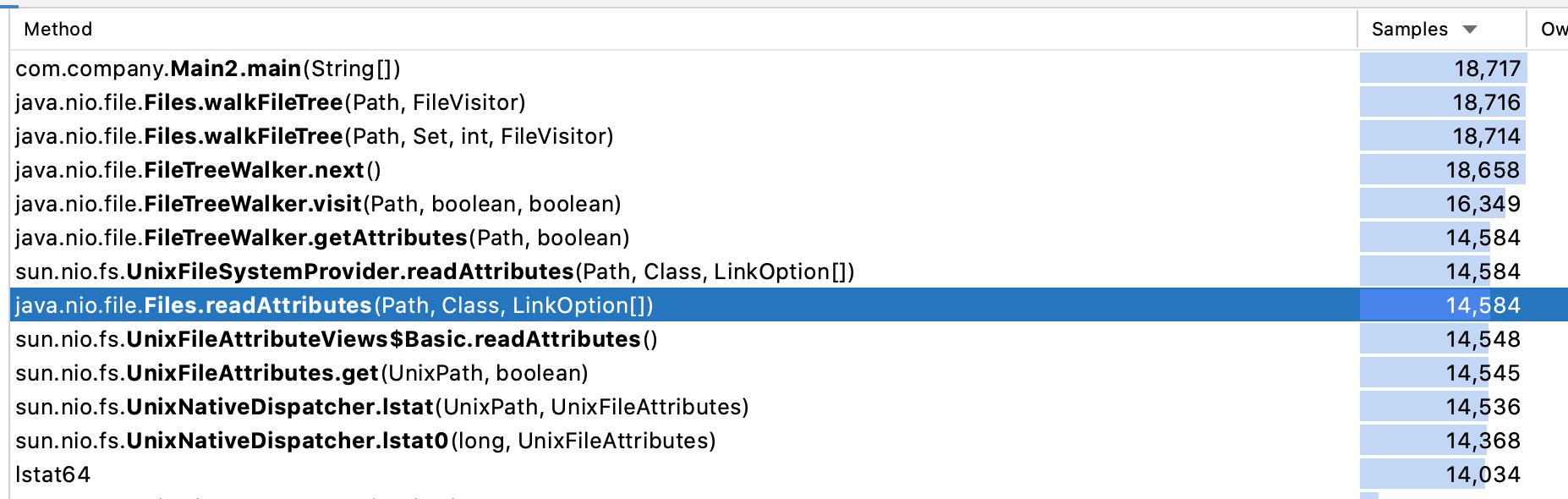
It started to look a native approach that uses another native APIs would work better.
Swift and Objective-C API
The very first experiment was to try macOS native APIs. I found the FileManager
and it’s enumerator API to list the files from Swift/Objective-C. The Swift program was as follows:
let fileManager = FileManager.default
let dirEnum = fileManager.enumerator(atPath: path)
let start = CFAbsoluteTimeGetCurrent()
var total = 0
while let file = dirEnum?.nextObject() as? String {
total += 1
}
let end = CFAbsoluteTimeGetCurrent()
print("total: ", total, "consume: ", (end - start), " s")
Unfortunately, it did not give the better result:
total: 942276 consume: 69.13790500164032 s
Program ended with exit code: 0
Golang
The next native language I decided was Go. I wrote a small program to list a folder recursively:
func scanDisk(home string) {
f, err := os.Open(home)
if err != nil {
log.Fatal(err)
return
}
defer f.Close()
dirs, _ := f.Readdirnames(-1)
if dirs != nil {
for _, name := range dirs {
scanDisk(path.Join(home, name))
}
}
}
It took approximately 80 seconds for that program to complete. Reading the code, I found out
Go uses the readdir function from POSIX API.
Next, I decided to give it a try in Native.
Basic C++ Implementation
At that point it turned more clear, the better performance could be
achieved by using a native APIs and with an attempt to avoid calling
unneeded system calls. In the basic implementation I use the same
readdir
function. One has to call opendir before and closedir after the
series of calls to the readdir. It yields enough information to
get a type of the directory entry. I’ve got the following C++ code:
int readOneDir(const std::string &dirName, std::queue<std::string> &newDirs) {
DIR *pDir = opendir(dirName.c_str());
if (pDir == nullptr) return 1;
int count = 0;
while (true) {
auto e = readdir(pDir);
if (e == nullptr) break;
if (e->d_name[0] == '.') {
if (e->d_name[1] == '\0') continue;
if (e->d_name[1] == '.' && e->d_name[2] == '\0') continue;
}
if (e->d_type == DT_UNKNOWN || e->d_type == DT_DIR) {
newDirs.emplace(dirName + '/' + std::string(e->d_name));
}
count++;
}
closedir(pDir);
return count;
}
int readRecursive(const std::string &dir) {
int count = 1;
std::queue<std::string> dirQueue;
dirQueue.emplace(dir);
while (!dirQueue.empty()) {
std::string home = dirQueue.front();
dirQueue.pop();
count += readOneDir(home, dirQueue);
}
return count;
}
With the output:
Time difference = 17641[ms]
Total files: 942330
Time difference = 17053[ms]
Total files: 942330
Time difference = 17038[ms]
Total files: 942330
Time difference = 16748[ms]
Total files: 942330
Time difference = 16865[ms]
Total files: 942330
So the program is able to scan all my 942330 files in approximately 17 seconds
(17641, 17053, 17038, 16748, 16865).
Is it possible to avoid doing that number of system calls to get the same list of files?
7x Speedup or macOS Cache
I was experimenting with the program above and decided to remove the out folder
from the processing. It is easy to implement by checking the e->d_name value. I added
the following line to the loop:
if (strcmp(e->d_name, "out") == 0) continue;
Adding that test reduced the number of files from one side, and gave a huge performance boost:
Time difference = 6358[ms]
Total files: 534067
Time difference = 2195[ms]
Total files: 534067
Time difference = 2224[ms]
Total files: 534067
Time difference = 2182[ms]
Total files: 534067
Time difference = 2155[ms]
Total files: 534067
It is AMAZING! Removing the out folder with compilers output made it return the answer in 2 seconds after a warmup.
It seems like the macOS has a disk-related cache that is not enough for all the files, but enough
for 534067 entries!
I’ve made another run of the tool directly on the out folder:
Time difference = 8334[ms]
Total files: 408117
Time difference = 1288[ms]
Total files: 408117
Time difference = 1290[ms]
Total files: 408117
Time difference = 1196[ms]
Total files: 408117
Time difference = 1194[ms]
Total files: 408117
Once again, we see that OS caching improves it greatly to 1.1 seconds!
It is still unclear, if one can tweak the cache size. I would be happy to make the cache at list twice big to make sure all my working copies on the computer fit into it. Please let me know in the comments if you have an idea on how to tune it.
macOS Specific Implementation
After reading internet and talking with friends we found there is a closer-to-the-kernel way to list files on macOS.
getdirentriesattr function help to make the macOS kernel do more work for us (if that one works). It seems deprecated in the recent versions of the macOS.
I’ve dug deeper and found out there is a better getattrlistbulk function in the kernel,
this one works for all filesystems, and it is not deprecated. You may find some
discussions
about that function in the mail-list or a man
page with a code sample. There is yet another code sample Gist.
The implementation is longer, but hopefully, it would reduce the number of system calls:
int readOneDir(const std::string &dirName, std::queue<std::string> &newDirs) {
int count = 0;
int dirfd = open(dirName.c_str(), O_RDONLY, 0);
if (dirfd < 0) return 0;
char attrBuf[1024*1024];
attrlist attrList{};
attrList.bitmapcount = ATTR_BIT_MAP_COUNT;
attrList.commonattr = ATTR_CMN_RETURNED_ATTRS | ATTR_CMN_NAME | ATTR_CMN_ERROR | ATTR_CMN_OBJTYPE;
for (;;) {
int retCount = getattrlistbulk(dirfd, &attrList, &attrBuf[0], sizeof(attrBuf), 0);
if (retCount <= 0) break;
char* entry_start = &attrBuf[0];
for (int index = 0; index < retCount; index++) {
count++;
char* field = entry_start;
uint32_t length = *(uint32_t *)field;
field += sizeof(uint32_t);
entry_start += length;
attribute_set_t returned = *(attribute_set_t *)field;
field += sizeof(attribute_set_t);
if (returned.commonattr & ATTR_CMN_ERROR) continue;
std::string name;
if (returned.commonattr & ATTR_CMN_NAME) {
attrreference_t name_info = *(attrreference_t *)field;
name = (field + name_info.attr_dataoffset);
field += sizeof(attrreference_t);
}
if (returned.commonattr & ATTR_CMN_OBJTYPE) {
fsobj_type_t obj_type = *(fsobj_type_t *)field;
if (obj_type == VDIR) {
newDirs.emplace(dirName + '/' + name);
}
}
}
}
close(dirfd);
return count;
}
The experimental run gives:
Time difference = 36195[ms]
Total files: 942330
Time difference = 37179[ms]
Total files: 942330
Time difference = 35888[ms]
Total files: 942330
Time difference = 37209[ms]
Total files: 942330
Time difference = 35302[ms]
Total files: 942330
The man getattrlistbulk command helps to get a documentation on that system call.
Unfortunately, this code works slower than the code above. It takes approximately 36 seconds
to list all my files that way.
A quick profiling in CLion
show that the most of the work is done in the kernel, in the getattrlistbulk call.
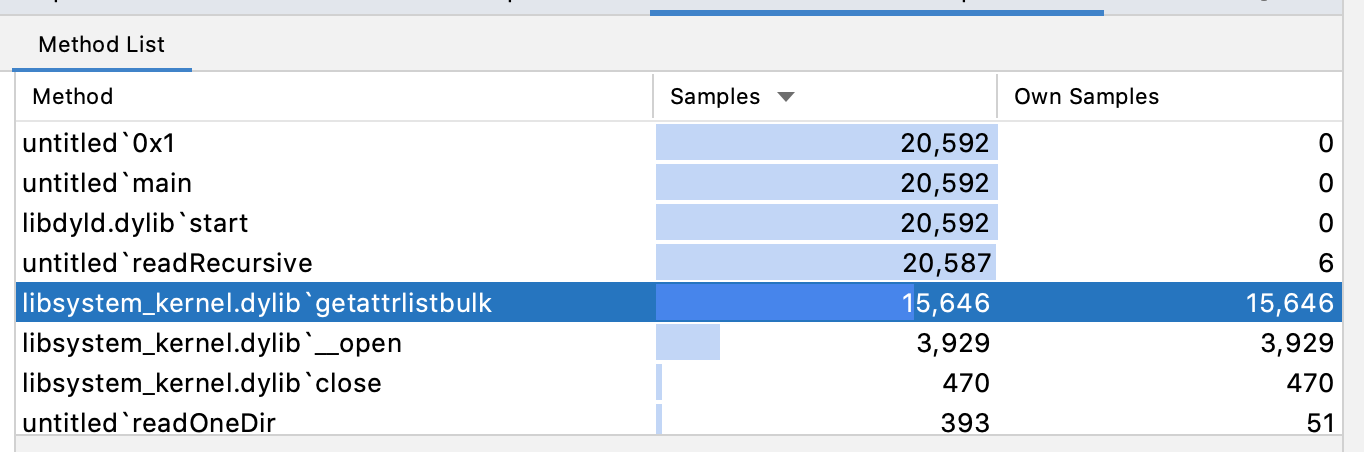
FTS API
I found a related post by Thomas Tempelmann on the same topic. Worth reading!
Yet another possibility is to use the FTS C-functions to iterate the filesystem:
static int compare(const FTSENT **one, const FTSENT **two) {
return (strcmp((*one)->fts_name, (*two)->fts_name));
}
int scanDirs(char* home) {
int count = 0;
char buff[222333];
char* pName = (char*)&buff[0];
strcpy(pName, home);
FTS* file_system = fts_open(&pName, FTS_COMFOLLOW | FTS_NOCHDIR | FTS_PHYSICAL | FTS_NOSTAT_TYPE, &compare);
if (file_system == nullptr) return 0;
while (fts_read(file_system) != nullptr) {
FTSENT *child = fts_children(file_system, 0);
while (child != nullptr && child->fts_link != nullptr) {
child = child->fts_link;
count++;
}
}
fts_close(file_system);
return count;
}
This code executes in approximately 26 seconds. The man fts_open command helps to learn
more about the API:
Time difference = 26353[ms]
Time difference = 25987[ms]
Time difference = 26439[ms]
Time difference = 26885[ms]
Time difference = 26648[ms]
Conclusion
There is no silver bullet, but I will continue the research to try to find a way to list files faster. At that point it looks like the whole filesystem abstraction is leaking. There are another approaches to represent is like S3, Minio, HDFS, or anything similar. FUSE and Docker filesystems look promising too, but I do not see how to apply that. Hope there is something I miss. I’ll be grateful to hear more ideas in the comments.